![]()
Si ha llegado a esta página dentro de un sistema de marcos,
y quiere salir de él, haga clic aquí:
http://jamillan.com/ecoling.htm
El libro
de medio billón de páginas
(La ecología lingüística de la Web)
José Antonio Millán
Versión ampliada del artículo publicado
originalmente en Revista de Libros (Madrid), nş 45 (septiembre del
2000), con el título: "El libro de mil millones de páginas. La ecología
lingüística de la Web".
rdl@seker.es
http://www.revistadelibros.com
Una versión preliminar de estos datos se presentó en la conferencia "Las redes de la lengua" dentro del ciclo: "Internet, la necesidad del conocimiento", Madrid, Círculo de Bellas Artes, 29 de noviembre de 1999
Mi agradecimiento a Juan Quetglas por haberme facilitado los ejemplos ecológicos a partir de mis descripciones formales.
Nota sobre navegación: figuran en azul los enlaces interiores del sitio, o interiores a una obra contenida en él; en verde, los enlaces a otra parte del mismo sitio, pero que representan de algún modo un excurso o desvío, y por último en rojo, en todos los casos, los enlaces ajenos
Para tener una idea de esta magnitud supongamos que alguien quisiera leer todo el conjunto de la Web a fecha de hoy (preciso esto porque los contenidos de las páginas están variando cada día, lo que hace que la masa total de páginas diferentes en periodos más amplios aumente aún más). Si dedicara a ello una jornada laboral normal, pero sin festivos ni vacaciones, tardaría más de veinticinco mil ańos… Pero esto no es todo: los contenidos que se vuelcan en los grupos de discusión (news groups) puede perfectamente cuadruplicar el contenido de la Web [3]. Y por último, el conjunto del correo electrónico que circula por el mundo supera con mucho las cifras anteriores: cada minuto se envían cinco millones de correos electrónicos [4]. Ya circulan más que la voz [5].
Pero los informes más recientes (julio del 2.000) de la compańía BrightPlanet [5bis] complican mucho las cosas. Para su autor, Michael K. Bergman, existe una Web invisible que tendría una extensión 500 veces mayor que la visible (que es la única que detectan los buscadores). Y su tamańo total sería de 550.000 millones —medio billón— de documentos.
* * *
A lo largo de la historia humana se han generado incontables sartas de discurso, y muchas de ellas se han remansado en tablillas, muros, papiros y libros. El saber total de la Antigüedad —al menos en su forma final, custodiado en la Biblioteca de Alejandría— se ha calculado en 0,8 terabytes (un terabyte es aproximadamente un millón de megabytes, o megas; un mega es algo menos del contenido de un disquete). Los veinte millones de libros de la Biblioteca del Congreso de Estados Unidos ocuparían (sin contar sus ilustraciones) 20 terabytes [6]. La totalidad de un corte actual de la Web visible daría 7,5 terabytes de texto [7], y la Web invisible (para BrightPlanet), 7.500 terabytes de información. Sí: la Red es ahora una inmensa biblioteca o, más bien —dada la interconexión que hay entre sus obras— un gigantesco libro. Lo realmente nuevo y asombroso de la situación actual no es sólo la cantidad, sino que esta masa gigantesca de texto sea directa e inmediatamente accesible.
Los esfuerzos por conocerla y navegarla han producido un hecho cualitativamente nuevo: la mediación de sistemas automáticos para la comunicación entre las personas que publican contenidos en la red, y quienes los buscan. Esta mediación, que tiene una gran base lingüística, va a ser el tema de estas páginas.
* * *
żComo conocemos que algo está en la Red? Porque alguien nos lo dice (por ejemplo, con un email: "echa un ojo a esto, que te interesará"); porque estamos en una lista de discusión sobre un tema y allí nos recomiendan unas páginas; o porque hemos acudido a un sitio web que reúne enlaces según cierto criterio. Estos mecanismos de filtrado colectivo —con todo y ser apasionantes— no nos ocuparán ahora. Nos centraremos más bien en los sistemas de mediación automática...
Un ejército de arańas surca la Red. Son mecanismos virtuales al servicio de los buscadores que, siguiendo los dictados de su programación, leen cada página que encuentran en su camino, y mandan las palabras que contienen (junto con información sobre dónde están) a enormes bases de datos. Acabadas de devorar todas las páginas de un sitio, seguirán los enlaces que encuentren hasta llegar a otro, y comenzar de nuevo. Gracias a ellas, los buscadores (de los que hay unos 400, aunque la cuarta parte de las búsquedas se hacen sólo a través de los siete o diez principales [8]) pueden responder a las preguntas de los usuarios: "páginas donde esté la palabra arańa y la palabra clavo". Altavista, por ejemplo, funciona así, y gracias a su acción contenidos que habrían permanecido ocultos a los ojos de cualquiera se pueden exhumar fácilmente.
Fijémonos que estamos en el dominio de la explotación del interior de los textos: el acceso a los documentos ha venido estando guiado primero por su descripción en archivos y bibliografías, y luego (una vez conseguidos) por las balizas textuales que el autor o el editor fijara (títulos de obras, de capítulos y apartados, índices), pero aquí estamos en el acceso a la palabra, a cualquier palabra del interior.
Los buscadores que indizan el contenido de las páginas nos sitúan frente a la Web —aunque matizaremos esto— como el sabio dotado de un volumen de Concordancias frente a las Sagradas Escrituras: en el dominio pleno.
Pero... ningún buscador indiza más allá del 50% de la Red, afirma Search Engine Watch [9], y en estos momentos es difícil saber qué proporción de Web abarca la suma de todos los buscadores (o, en otras palabras, qué porción de la Web es opaca a cualquier búsqueda). En febrero de 1999, un estudio de la revista Nature (citado en [7]) calculaba que entre todos los buscadores no se cubría más que el 42% de la red. La situación habría mejorado, pero en cualquier caso parece mantenerse la tendencia manifestada entonces (que se indizan sobre todo sitios de EEUU, y en especial los más visitados, y los comerciales más que los de educación). Como consecuencia, o las lenguas minoritarias en la Red se dotan de herramientas y estrategias propias [10], o quedarán en una zona de sombra...
A estos problemas se unen los que ha generado el informe de BrightPlanet [5bis]. Para él, la acción de los buscadores se extiende sólo sobre la llamada "Web visible", que representa gráficamente así:

Grafíco 1. La Web superficial, la que controlan los buscadores.
Tomado de "The Deep Web: Surfacing Hidden Value" [5bis]
Pero además habría un número muy grande de bases de datos que generan el contenido dinámicamente, es decir: que no constituyen páginas web tradicionales a las que se llega por enlaces desde otras. Como éste es el sistema que tienen los buscadores clásicos para conocer qué hay, el informe concluye que la "Web profunda" es inaccesible a ellos.
Para saber qué contiene la "Web profunda" no hay más remedio que lanzar interrogaciones a las bases de datos, que es el procedimiento que ha seguido el software LexiBot de Bright Planet. Hemos adelantado antes su conclusión: que la Web invisible es unas 500 veces mayor que la visible.
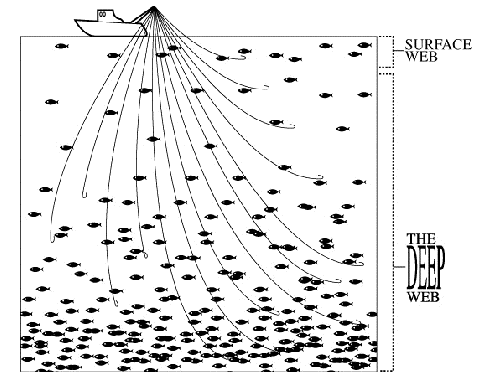
Gráfico 2. La Web profunda, la que presuntamente controla el software
de BrightPlanet.
Tomado de "The Deep Web: Surfacing Hidden Value" [5bis].
La red del gráfico 1 simboliza la acción de las arańas, saltando de enlace en enlace,
mientras que los anzuelos de este gráfico representan los ataques selectivos a las bases
de datos.
* * *
Hay sitios dedicados a monitorizar las demandas que los usuarios dirigen a los grandes buscadores (recordemos: ˇtodo en la Red es transparente!), y produce una extrańa impresión asistir al rosario de peticiones que se van desgranando hora a hora: se puede hacer la experiencia en Wordtracker. Esta empresa ha calculado cuántas consultas a los buscadores se hacen diariamente: el asombroso resultado son 250 millones [11]. A partir de ellas Wordtracker crea una base de datos de 30 millones de términos (las palabras y frases por las que busca la gente), que se renueva cada dos horas. Luego hablaremos de la importancia comercial que tiene conocer estas búsquedas
żY qué es lo que persigue la gente en la Red? Hay una demanda clásica, mantendida constantemente desde que se empezó a estudiar la exploración de la web: sex (y podemos sentir aquí ecos del Arcipreste: "El hombre por dos cosas se mueve, la primera..."). Según Mall-Net [12], sex es la palabra que lanzan más del 5% de las personas que se asoman a un buscador. Durante ańos ha sido la más pedida: sólo recientemente ha sido superada por MP3 (el famoso formato de compresión en el que circula la música).
Algunas palabras o frases adquieren notoriedad durante unas horas o días, y luego desaparecen de pronto. Mall-Net las registra y suele comentarlas. Por ejemplo: el 15 de mayo pasado hubo un pico de demandas sobre car security. La causa más probable fue que el primer ministro de Cachemira (junto a cinco personas más) murió por una bomba puesta en su coche. Las demandas subieron una hora después de que un despacho de Reuters diera la noticia.
Aun con la ayuda de las grandes bases de datos de los buscadores, localizar algo en la Red no es tarea fácil; exige habilidades detectivescas de un tipo muy especial (y que antes estaban confinadas sólo a profesionales de la documentación). Hay que saber qué expresión es más probable que aparezca relacionada con el material que se persigue, huir de los términos que se pueden emplear en más de un campo, saber combinar varias palabras clave mediante operadores booleanos —Y, O, NO— para refinar la búsqueda (Lutero Y NO King). Todo esto ya se empieza a enseńar en los colegios (avanzados).
Mientras tanto, ya hay software que permite que las búsquedas se abran morfológicamente (preguntar por conducir y acceder también a conduje y a conducción) y semánticamente y por variantes de lengua (de conducir llegar a manejar y guiar). El objetivo último es que se pueda llegar a consultar los buscadores usando directamente la lengua natural, sin tener que reducirla a fórmulas lógicas. Al fin y al cabo, la gente ya tiende a formular búsquedas mediante pequeńas expresiones (el 67,5 de las personas preguntan mediante fórmulas de dos o más palabras, según Search Engine Watch [13]).
El siguiente paso es romper los límites de la lengua. Hay buscadores que suplementan la demanda del usuario con traducciones (y al preguntar por conducir se buscaría simultáneamente conduire y drive), de modo que la consulta llevará a sitios en varias lenguas. Un software de traducción, incorporado ya en muchos casos al mismo buscador, permitirá que el consultante poco políglota se entere (aproximadamente) del contenido de esos sitios... Y por último, ya hay programas que hacen resúmenes aceptables. żBuscar algo y encontrarlo en cualquier lengua? Cada vez es más posible...
A propósito (y aunque no es el objeto directo de este artículo): del panorama descrito se deduce en seguida que las tecnologías de la lengua van a tener una gran importancia económica y estratégica. La pregunta "ża quién pertenece el espańol?" tenía hasta ahora la respuesta retórica (pero real): "ˇal pueblo que lo habla!". Pero su prolongación digital, "żquién va a poser las tecnologías lingüísticas que permitirán a los sistemas automáticos usar el espańol?", puede tener respuestas desagradables para nuestra economía y soberanía cultural (y la de los demás países hispanohablantes, por cierto...)
* * *
[Parte uno de cuatro]
[1] Inktomi Web Map, http://www.inktomi.com/webmap.htm
![]()
[2] Extrapolo a partir de los datos de Nature en febrero
de 1999, véase la referencia en la nota 7, abajo ![]()
[3] Al menos eso es lo que afirmaba Dejanews, http://www.dejanews.com
en febrero de 1998 ![]()
[4] [Próximamente: ahora no encuentro la referencia, pero juro
que lo leí] ![]()
[5] Cada hora se emiten 35 millones de mensajes de voz.
Declaraciones de Ben Verwaayen (vicepresidente de Lucent Technologies), "Las actuales
oportunidades de la ‘nueva economía’", 5 Días, 14 de junio del
2000 ![]()
[5bis] Su página principal es http://www.completeplanet.com/.
El documento "White Paper. The Deep Web: Surfacing Hidden Value", por Michael K.
Bergman con Mark Smither y Will Bushee, © 2000 BrightPlanet.com LLC, se
puede bajar en versión Word en http://www.completeplanet.com/
Tutorials/DeepWeb/index.asp. Sus datos han comenzado a ser discutidos y matizados,
pero aún no he leído críticas fundamentadas, que probablemente tarden algún tiempo.![]()
[6] Este dato y el anterior provienen del Internet
Archive, http://www.archive.org
![]()
[7] El famoso estudio de Steve Lawrence y C. Lee Giles, del
NEC Research Institute, que apareció en el número de 8 de julio del 1999 de Nature
(resumen en http://www.wwwmetrics.com) daba, para febrero de 1999, 800
millones de páginas web, con 6 terabytes de datos de texto. Extrapolo para los 1.000
millones que calcula más recientemente Inktomi [1].
BrightPlanet [5bis] asigna a la Web visible 19
terabytes de información. ![]()
[8] http://www.wordtracker.com ![]()
[9] http://www.searchenginewatch.com/
reports/sizes.html ![]()
pub/indexem/indexem.htm
[11] http://www.wordtracker.com/
articles/predict.php3.htm ![]()
[12] http://www.mall-net.com/se_report/ ![]()
[13] http://www.searchenginewatch.com ![]()
Última versión, 2 de octubre del 2000