Ayudando al OCR
07 septiembre 2007 08:48
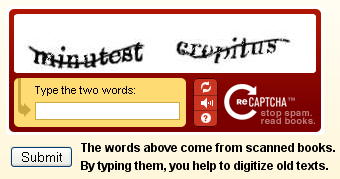
Captcha es el sistema mediante el cual un sitio web con intervención del público se defiende de los programas que se dedican a meter spam; por ejemplo; muchos blogs proponen a quienes quieren escribir un comentario que escriban el texto de una secuencia de letras deformada o borrosa que se les ofrece. Esta tarea exige (por el momento) un ser humano: los programas no la cumplen.
Pues bien: cuenta Barrapunto que ha nacido reCaptcha, de la mano de los mismos investigadores de la universidad Carnegie Mellon que crearon su antecesor. Su peculiaridad es que el texto que propone para interpretación proviene del escaneado de libros: son palabras que el reconocimiento óptico de caracteres no puede interpretar. El programa de OCR detecta una palabra problemática y reCaptcha la ofrece como clave de acceso, emparejada con otra palabra cuya interpretación se conoce (y que sirve de control). Las palabras dudosas se ofrecen cierto numero de veces, hasta que la lectura se confirma.
ReCaptcha está funcionando por el momento como una ayuda para las digitalizaciones del Open-Access Text Archive, del Internet Archive. Teniendo en cuenta que cada día se resuelven 60 millones de Captchas, que llevan de media 10 segundos, su suma daría 150.000 horas de trabajo al día, que reCaptcha pondría al servicio de la digitalización de libros. No está mal, ¿no?
Etiquetas: Digitalización, Lo hacemos entre todos, Mención de honor
![]()
![]()



0 Comentarios:
Publicar un comentario en la entrada
<< Home